Space Based Architecture
Space-based architecture is a software architecture pattern designed for highly-scalable, distributed systems that can handle large workloads and accommodate varying demand. It relies on the principles of partitioning and replication of data and processing components, allowing for parallelism, fault tolerance, and load balancing across the system.
This is the sixth post in a series of posts about software architectures. The previous posts are:
Most web-based applications follow the same request flow: a request originates in the browser, hits the web server, the application server, and finally, the database server. As the user load increases, bottlenecks start forming, first at the web layer, then the application server, and then the database.
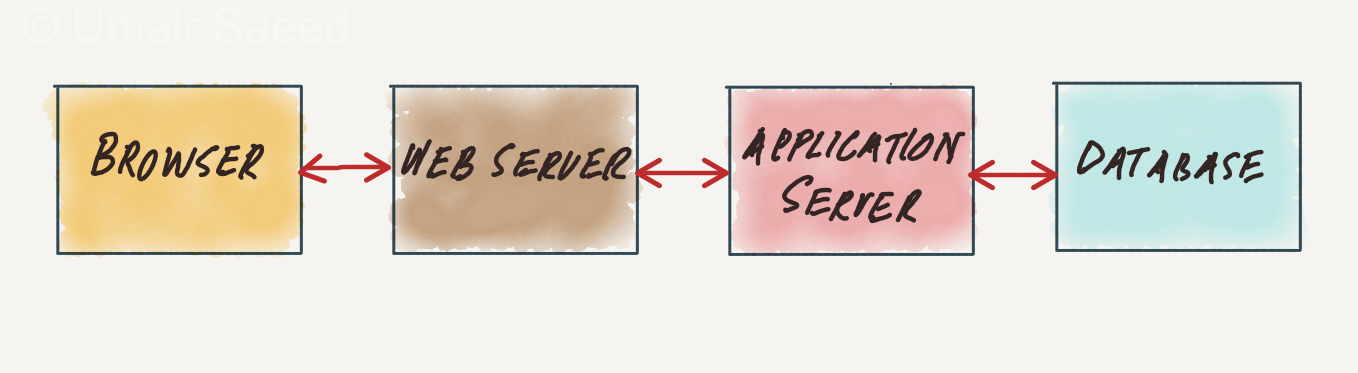
The usual response is to keep scaling each layer horizontally, starting with the web server. However, once we get to the database server, scaling out becomes more difficult and expensive.
Space-based architecture addresses these problems. Space-Based Architecture (SBA) is a distributed computing architectural pattern that aims to achieve scalability, fault tolerance, and high performance. It gets its name from the concept of tuple space, the technique of using multiple parallel processors communicating through shared memory.
The space-based architecture style is specifically designed to address problems involving high scalability, elasticity, performance, and high concurrency issues. It is often the architecture of choice for financial applications, gaming platforms, and large-scale simulations.
Overview
The core insight of this architecture is to remove the database as a synchronous constraint in the system and instead leverage replicated in-memory data grids. The core components of Space-Based Architecture are as follows.
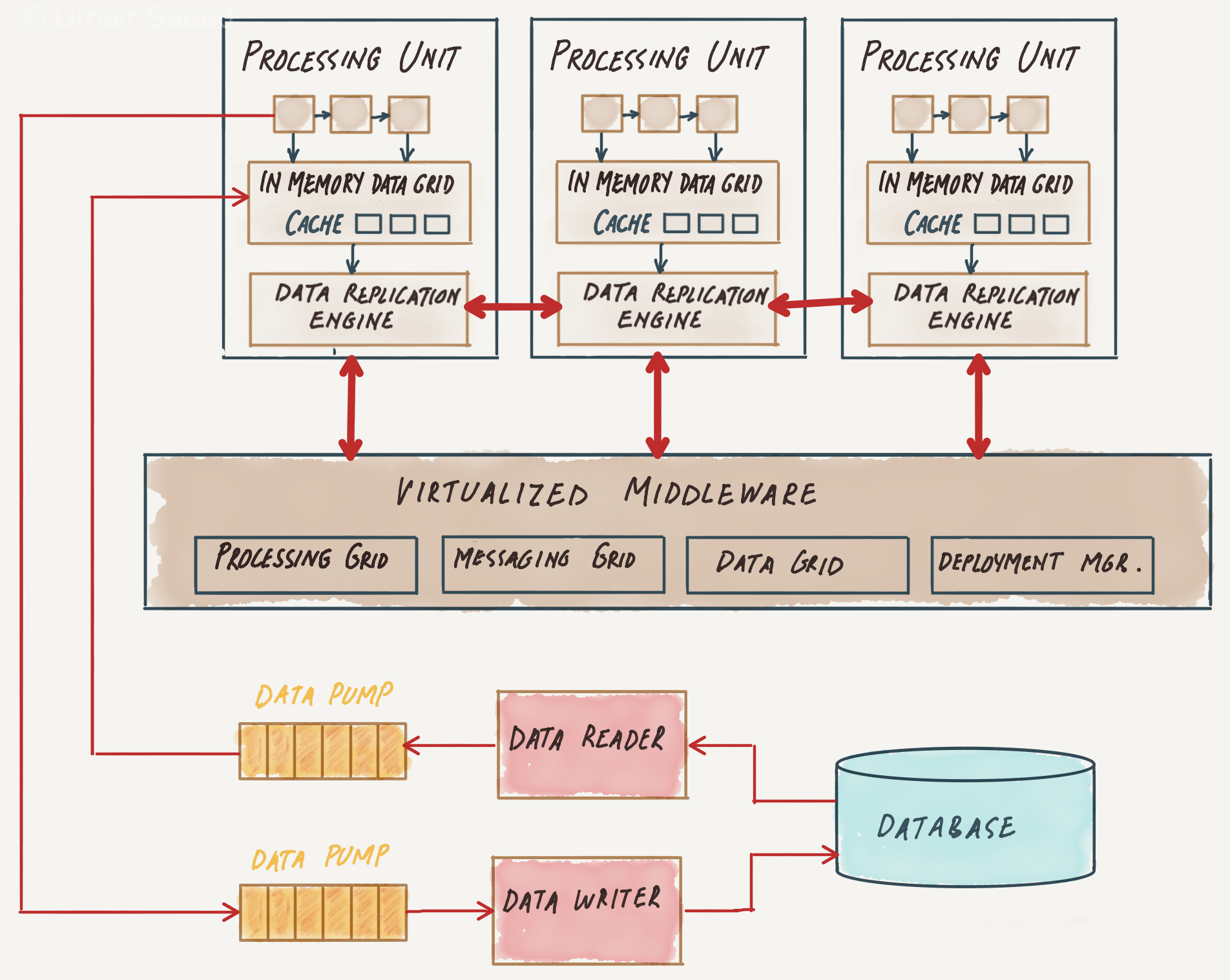
Processing Units (PU)
A processing unit (PU) is an individual node or container that encapsulates the processing logic and the data it operates on. A PU is responsible for executing the business logic and can be replicated or partitioned for scalability and fault tolerance. A PU usually includes web-based components as well as backend business logic.
In addition to the application logic, the processing unit also contains an in-memory data grid and replication engine that works with the corresponding module in the virtualized middleware.
Virtualized Middleware
This layer handles the shared infrastructure concerns for this architecture. It has the following components:
The Data grid
The data grid is arguably the most crucial component of this architecture. A given request can be assigned to any of the available processing units, so each PU must contain the same data in its in-memory grid.
The data grid is a shared, associative distributed memory responsible for synchronizing data between the processing units. In other words, the data grid is the component responsible for building a Tuple space.
The Messaging grid
Once a request comes into the virtualized middleware, the messaging grid determines which active PUs are available and forwards the request to those PUs.
The processing grid
The processing grid orchestrates the processing of a request when it spans multiple PUs.
Deployment manager
Manages the startup and shutdown of the PUs, starts up new PUs to handle any additional load, and shuts down PUs once they are no longer needed.
Data Pumps
Data pumps are responsible for marshaling data between the database and the processing units. Once a PU instance receives a request and updates its cache, that processing unit becomes the owner of the update. It is, therefore, responsible for sending that update through the data pump so that the database can be updated eventually.
Data pumps are typically implemented using messaging.
Data Writers and Readers
A data writer accepts messages from a data pump and updates the database with the information.
Similarly, a data reader reads data from the database and sends it to the processing unit. In space-based architecture, the data readers are only used during redeployment or crash-recovery of all the processing unit instances of the same named cache.
Analysis of Quality attributes
Deployability (Medium)
SBA enables easy deployment of components, as they can be packaged into independent and self-contained units, allowing for updates and deployments without impacting the entire system.
Fault Tolerance (Medium)
Data partitioning, replication, and redundancy mean that a failure in one node can be mitigated by rerouting requests to other nodes, minimizing the impact on the overall system.
On the other hand, the system relies on the eventual consistency of data leading to a medium score for fault tolerance.
Scalability (High)
With the database no longer a bottleneck, this architecture scales extremely well by leveraging in-memory data caching and replication. The ability to dynamically bring up PUs as the load increases also contributes to a high scalability score for this architecture.
Processing millions of concurrent users is possible using this architecture style.
Elasticity (High)
Same as scalability.
Reliability (High)
Data redundancy and replication mechanisms contribute to the system’s overall reliability, ensuring data persistence and availability.
Performance (High)
Performance is another core strength of this architecture. Parallel processing and in-memory caches for reading data lead to a high-performance score.
Modularity (High)
The components within space-based architecture are built and deployed as independent, self-contained units. Often, off-the-shelf components are used as sub-components of the virtualized middleware, helping the modularity of the overall system.
Extensibility (High)
The architecture’s data partitioning and parallel processing capabilities make it easier to accommodate new data-intensive tasks or additional processing requirements.
Similarly, the reliance of this architecture on message-passing or event-driven communication between components makes it easier to build and integrate new functionality.
Testability (Low)
Testing individual components can be straightforward, but testing interactions between the nodes and ensuring data consistency across nodes is challenging.
Simplicity (Low)
Space-based architecture is a highly complex architecture style due to caching and eventual consistency of the primary data store, which is the ultimate system of record.
Overall Cost (Low)
Compared to other architecture styles, space-based architecture is expensive, primarily due to infrastructure costs associated with licensing fees and managing and maintaining multiple nodes.
Conclusion
Implementing space-based architecture can be more complex than traditional monolithic architectures, requiring a deep understanding of distributed systems and data partitioning strategies. In addition, ensuring data consistency across replicated and partitioned data can be challenging, often requiring eventual consistency models or sophisticated synchronization mechanisms.
Space-based architecture offers significant advantages for systems requiring high scalability, fault tolerance, and adaptability, making it an excellent choice for applications such as large-scale e-commerce platforms, distributed data processing, and real-time analytics. For instance, this is a good choice for a large-scale online ticketing system as it can efficiently handle varying traffic spikes during sales events.