Pipeline Architecture
A pipeline architecture is a monolithic architecture style, which means a single deployment unit for all of the code. The essential characteristic of pipeline architecture is that data or tasks are processed in a series of stages. Each stage receives the output from the previous stage, processes it, and passes it on to the next stage.
This is the third post in a series of posts about software architectures. The previous posts are:
Overview
There are two significant parts of this architecture: pipes and filters. As a result, this is also known as the pipes and filters architecture.
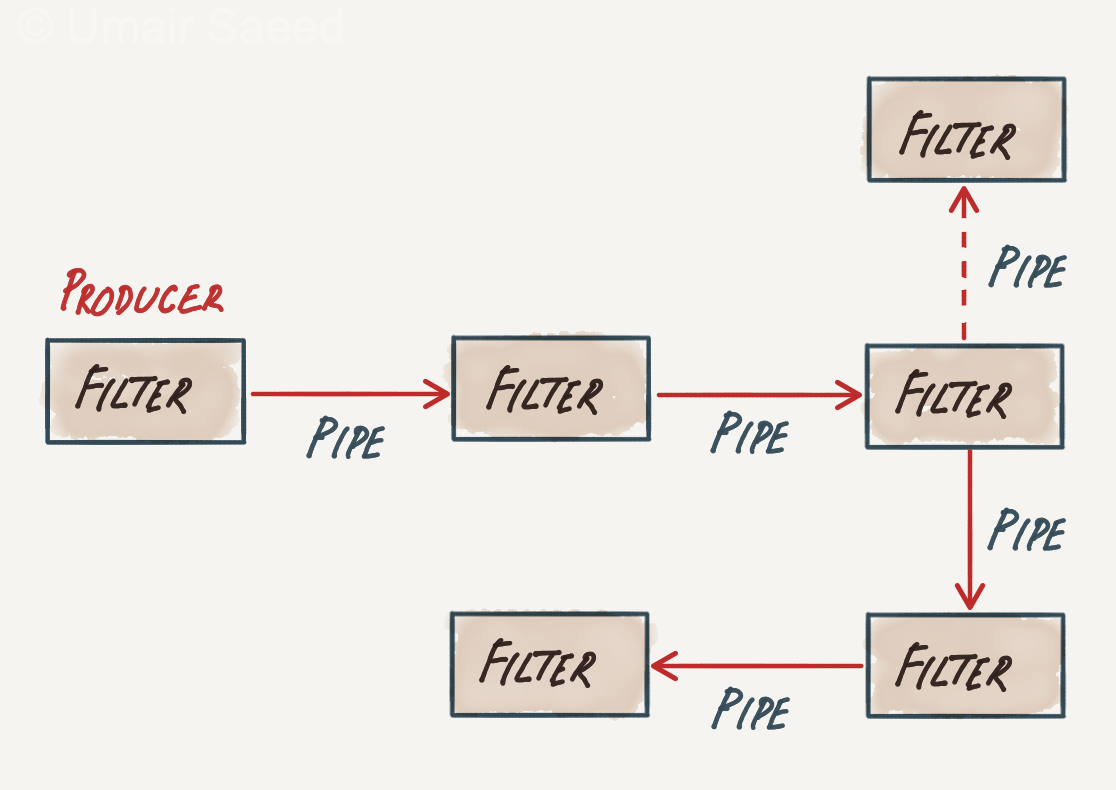
Pipes form the communication channel between the filters. Each pipe is unidirectional and point-to-point.
Filters are self-contained processing units and are generally stateless. Ideally, each filter should perform one task only. A sequence of filters should handle composite tasks. There are four distinct types of filters:
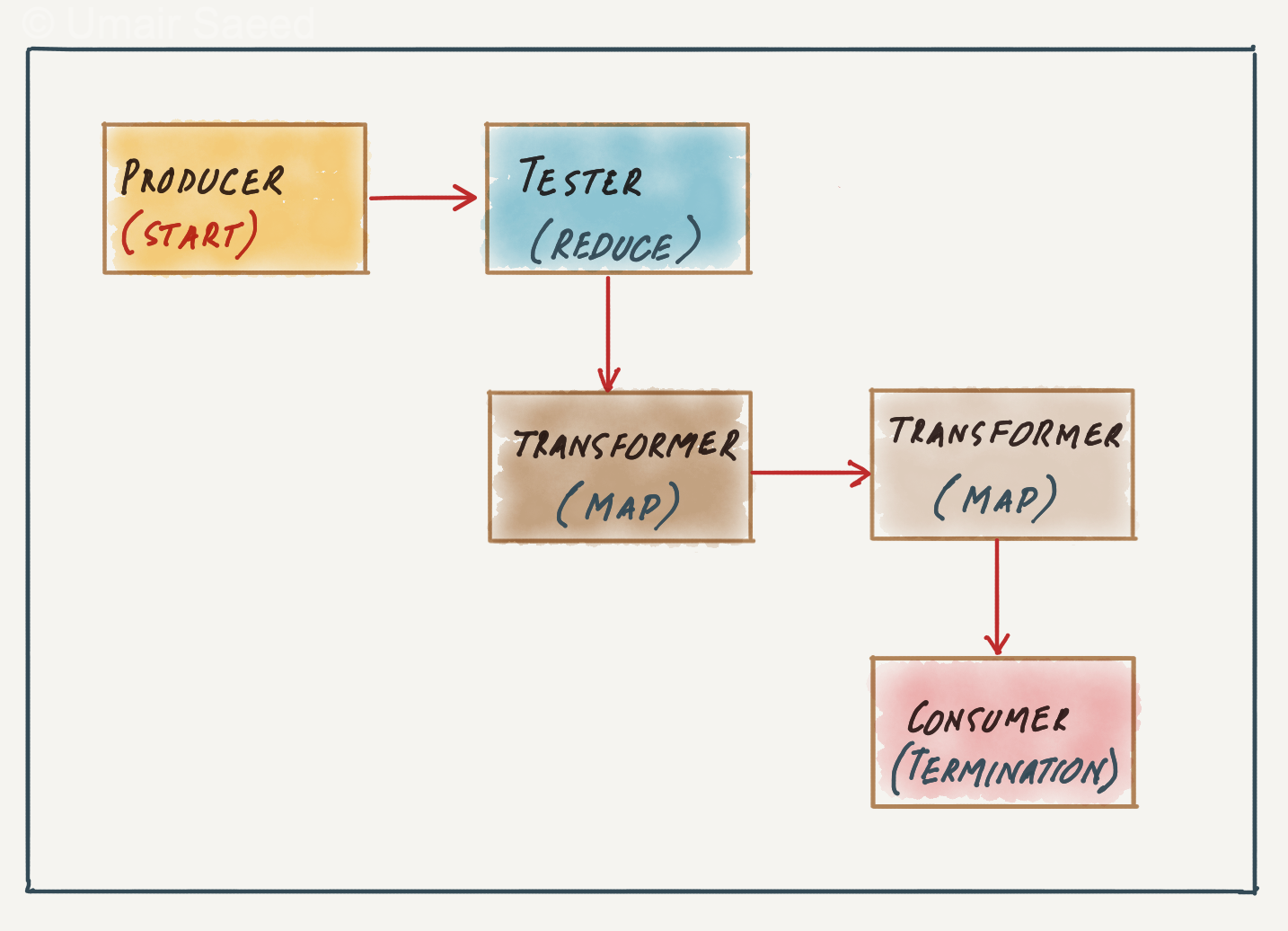
- Producer: The starting point of a process. A producer is outbound only and does not take any input.
- Transformer: A transformer accepts input, performs a transformation on some or all of the data, and sends it out as output. It is equivalent to the map function in functional programming.
- Tester: A tester accepts input, tests one or more criteria, and then optionally produces an output based on the test. It is equivalent to the reduce function in functional programming.
- Consumer: The consumer is the termination point for the pipeline flow. Consumers sometimes persist the results to a database or display the final results on the user interface.
The diagram below shows an example of a pipeline with four types of filters.
Analysis of Quality Attributes
Deployability (Low)
This architecture has a low score on deployability due to its monolithic nature. The entire application or website must be deployed as one unit, making frequent deployments hard. Even the simplest change requires a complete build and deployment of the whole application.
Fault Tolerance (Low)
Pipeline architectures don’t support fault tolerance very well due to monolithic deployments and the lack of architectural modularity. If one part of a pipeline architecture causes an out-of-memory error, the entire application unit is impacted and crashes.
Scalability (Low)
Due to its monolithic nature, the overall design of this architecture bakes in the scalability considerations. As a result, little can be done post-deployment to react to increased load.
Elasticity (Low)
Similar to scalability, this architecture style scores low for elasticity, as it cannot respond to increased user spikes beyond its baked-in capacity.
Reliability (Medium)
A pipeline architecture is the middle of the road for reliability. Given its medium scores on modularity testability, each stage of the pipeline can be verified independently.
On the other hand, the monolithic nature, a bug (e.g., out-of-memory exception) in any part of the code risks bringing down the entire application, which hurts the reliability score for this architecture.
Performance (Medium)
The use of pipes for communication between filters can introduce latency. Performance degradation can scale linearly with the number of filters in the path, leading to worse performance than tightly integrated monolithic designs.
In some cases, creating parallel pipelines allows multiple stages to work on different data segments concurrently. This option leads to a medium overall score for performance.
Modularity (Medium)
Even though the overall application is monolithic, the filters are typically built as separate modules and thus help with the modularity score of this architecture.
Extensibility (Medium)
We can add additional functionality via additional filter and transformer nodes, which makes it easier to add new paths of processing within this architecture. However, this cannot be done dynamically due to the monolithic nature of this architecture, resulting in a medium score.
Testability (Medium)
The fact that the filters can be built as independent modules helps with the testability of this architecture. However, the score is pegged as a medium due to the monolith nature and low deployability.
Simplicity (High)
The pipeline architecture simplifies the design of individual stages, making it conceptually easy to understand.
Overall Cost (High)
Pipeline architecture can reduce development and maintenance costs through modularity and extensibility. Due to its monolithic nature, it is relatively easy to build and maintain, which helps with its costs.
Conclusion
The pipeline architecture pattern appears in a variety of applications, especially tasks that facilitate simple, one-way processing. For example, many Electronic Data Interchange (EDI) tools use this pattern, building transformations from one document type to another using pipes and filters.
A pipeline architecture is most effective for problems that can be broken down into a series of independent, sequential processing steps. It might not be suitable for problems that require complex dependencies or parallel processing.